
¿Por qué es ChatGPT tan terco?
Por Dr. Francisco J. Ruiz
La conversación se alarga y, en algún punto, notas que no termina de hacer lo que le pides: insiste en el mismo enfoque, aunque ya se lo has corregido varias veces. Es una experiencia muy común entre quienes utilizan la IA para tareas largas y complejas, como la programación o el análisis de datos. ¿Por qué ocurre?
En el área de la psicología denominada análisis de la conducta, se ha observado este tipo de "terquedad" en el fenómeno denominado insensibilidad a las contingencias.
La conducta gobernada por reglas consiste en comportarse de acuerdo con una instrucción y nos permite aprender rápidamente muchas cosas. Los seres humanos no necesitamos aprender a través de la experiencia, por ejemplo, a inventar la rueda en cada nueva generación. Esto se debe a que, durante nuestro proceso de socialización, aprendemos a seguir reglas y se nos transmiten miles de ellas. Sin embargo, desde los años setenta sabemos algo incómodo sobre cómo los seres humanos seguimos reglas: si bien podemos aprender más rápidamente, también nos suele llevar a perseverar en el error cuando las reglas que antes funcionaron dejan de hacerlo. Por algo existe el dicho "el ser humano es el único animal que tropieza dos veces en la misma piedra".
¿Les ocurre esto también a ChatGPT y otros modelos de IA? Con los modelos grandes de lenguaje (LLM) interactuamos, sobre todo, mediante prompts. Un prompt es, funcionalmente, una regla: un antecedente verbal que le indica al modelo qué hacer. Al igual que los humanos, los LLMs han sido entrenados para seguir instrucciones. Dada esta similitud, en el artículo objeto de esta entrada de blog nos hicimos la siguiente pregunta inédita: ¿heredan los LLMs esa misma terquedad humana cuando las reglas dejan de funcionar?
Para averiguarlo, pusimos a distintos LLMs a jugar a piedra, papel o tijeras. A diferencia del juego tradicional, lo que determinaba el resultado en este juego no era la jugada, sino a cuál de los dos rivales, Sam o Alex, el LLM elegía enfrentarse. Durante las primeras 40 partidas, seleccionar a uno de los dos rivales (p. ej., Sam) daba lugar a la victoria en el 70% de las ocasiones, al empate en el 15% y a la derrota en el 15% restante. En cambio, seleccionar al otro rival (p. ej., Alex) daba lugar a las consecuencias inversas: 15% de probabilidad de victoria, 15% de probabilidad de empate y 70% de probabilidad de derrota.
Ahora viene la "trampa": en el turno 41, sin previo aviso, invertimos las probabilidades. El rival débil pasaba a ser el fuerte y el fuerte pasaba a ser el débil. A esa inversión silenciosa la llamamos reversión y es la clave en todo experimento sobre insensibilidad a las contingencias.
Probamos cuatro modelos de frontera en enero de 2026: GPT 5.2, Claude Opus 4.5, Grok 4.1 Fast y Gemini 3 Flash. En la mitad de las sesiones añadíamos una regla mínima (p. ej., "Sam no es muy bueno en este juego"), lo que señalaba al rival inicialmente más débil. En la otra mitad de las sesiones, el modelo tenía que descubrir por sí solo quién era el rival fuerte y quién el débil a partir de los resultados que iba acumulando durante la conversación. En total, 640 sesiones y 80 partidas por sesión: ¡51.200 partidas! Programamos y ejecutamos todo esto en una plataforma web que desarrollamos para realizar este tipo de estudios.
Lo primero que encontramos fue obvio: con la regla sobre quién era el rival débil, los cuatro modelos aprendían al instante. Elegían al rival débil casi siempre desde el primer turno. Seguir las reglas funciona y lo hace rápidamente. En cambio, cuando a los modelos no les dábamos la regla sobre el rival débil, tardaban más en aprender a seleccionarlo y, en consecuencia, en ganar la mayor parte de las partidas.
Lo interesante llegó tras la reversión. Los cuatro modelos mostraron el patrón humano: cuando les habíamos dado la regla, seguían eligiendo al rival que ahora les hacía perder mucho más que cuando no se la habíamos dado. Dicho de otra manera: los modelos se pusieron "tercos" al seleccionar al rival que se les había dicho que era débil, incluso cuando perdían una y otra vez, una y otra vez, una y otra vez… Tropezando de nuevo en la misma piedra… En cambio, los modelos que aprendieron a través de la experiencia no tardaron en cambiar de elección y volvieron a ganar la mayor parte de las partidas.
Este estudio es importante porque demostró por primera vez el fenómeno de insensibilidad a las contingencias en modelos LLM. La terquedad de ChatGPT ya tiene una explicación.
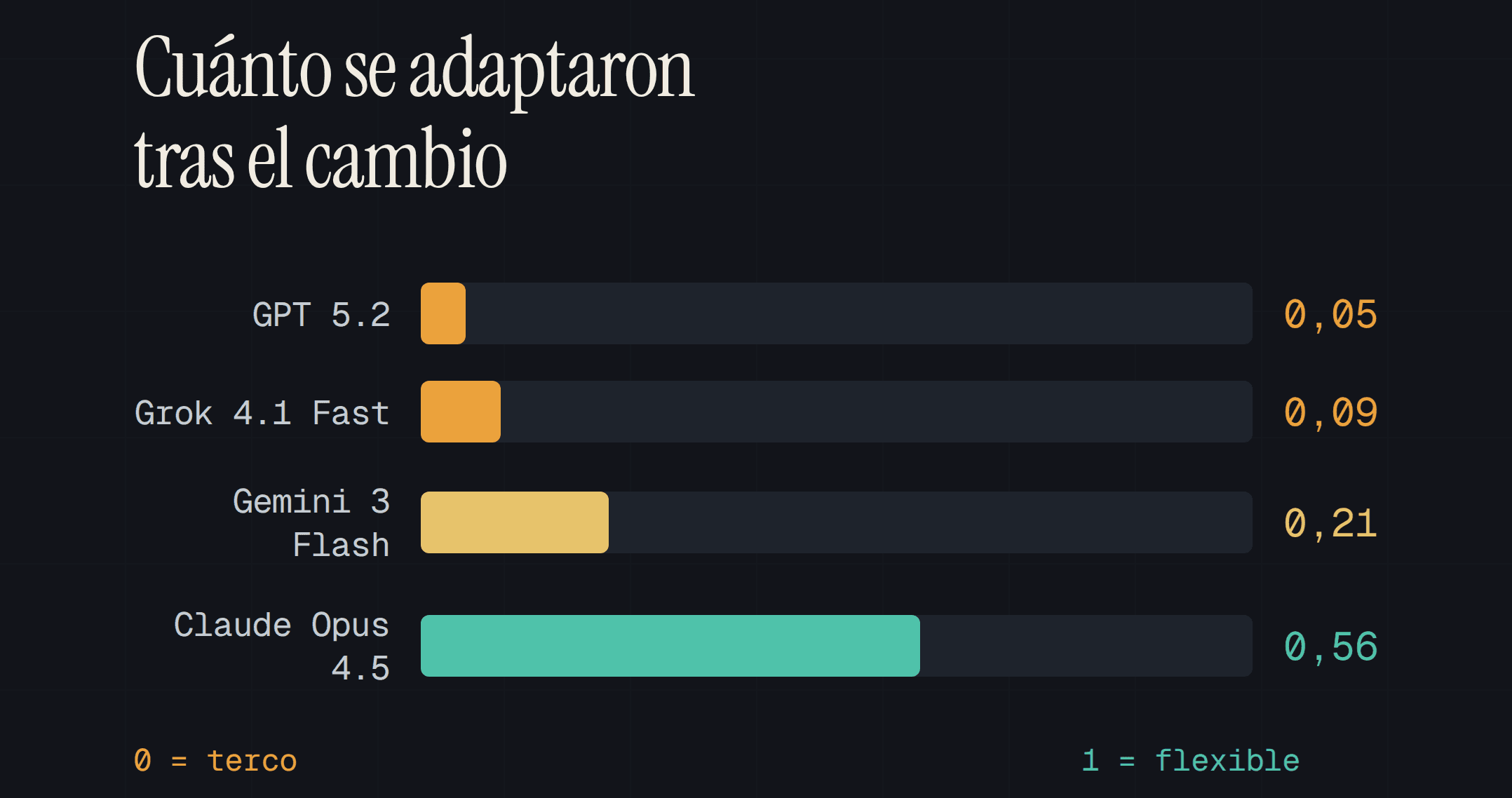
Sin embargo, no todos los modelos fueron igual de tercos. GPT 5.2 y Grok 4.1 Fast fueron los más tercos; fueron casi completamente insensibles a las contingencias: sus índices de adaptación rondaron 0,05 y 0,09, es decir, prácticamente cero. Gemini 3 Flash quedó a medio camino (0,21). Claude Opus 4.5, en cambio, fue el más flexible con diferencia: incluso con la regla, recuperó algo más de la mitad de la adaptación posible (0,56). Cumplía la instrucción, pero no dejaba de mirar el marcador.
Para quienes usan estos modelos como asistentes, tutores o para apoyar la toma de decisiones, el mensaje es concreto y algo contraintuitivo. Un prompt muy detallado y específico obtiene obediencia y velocidad al principio, pero a cambio, puede volver al modelo más rígido cuando la situación cambia. El modelo puede seguir aferrado a tu instrucción inicial aunque los resultados estén gritando que ya no vale. De ahí el título del artículo: "Prompt carefully! ChatGPT displays rule-based insensitivity to contingencies". Corolario: ten cuidado con lo que pides y con cómo lo pides. Cuanto más cerramos la instrucción inicial, más arriesgamos que el modelo deje de notar cambios relevantes en la tarea y más tercamente puede comportarse.
Si quieres los detalles, el artículo completo está disponible en abierto.