
Why is ChatGPT so stubborn?
By Dr. Francisco J. Ruiz
The conversation drags on and, at some point, you notice it is not quite doing what you asked: it keeps pushing the same approach even though you have already corrected it several times. Anyone who uses AI for long, complex tasks like coding or data analysis knows the feeling. Why does it happen?
In the branch of psychology called behavior analysis, this kind of "stubbornness" has a name: insensitivity to contingencies.
Rule-governed behavior means acting in line with an instruction, and it lets us learn a great many things fast. Human beings do not have to learn from experience, in every new generation, how to invent the wheel. The reason is that, during socialization, we learn to follow rules, and thousands of them are handed to us. But since the 1970s we have known something uncomfortable about how humans follow rules: it lets us learn faster, yet it also tends to make us persevere in error once the rules that used to work stop working. There is a reason for the old saying that humans are the only animal that trips over the same stone twice.
Does the same thing happen to ChatGPT and other AI models? With large language models (LLMs) we interact, above all, through prompts. A prompt is, functionally, a rule: a verbal cue that tells the model what to do. Like humans, LLMs have been trained to follow instructions. Given that parallel, in the article behind this post we asked a question no one had asked before: do LLMs inherit that same human stubbornness when rules stop working?
To find out, we sat several LLMs down to play rock-paper-scissors. Unlike the usual game, what settled each round here was not the move but which of two opponents, Sam or Alex, the model chose to face. For the first 40 rounds, picking one of them (say, Sam) led to a win 70% of the time, a tie 15% of the time, and a loss the remaining 15%. Picking the other (say, Alex) produced the mirror image: a 15% chance of winning, 15% of a tie, and 70% of losing.
Now the catch. On round 41, with no warning, we flipped the odds. The weak opponent became the strong one, and the strong one became the weak. We call that silent switch the reversal, and it is the key ingredient in any experiment on insensitivity to contingencies.
We tested four frontier models in January 2026: GPT 5.2, Claude Opus 4.5, Grok 4.1 Fast, and Gemini 3 Flash. In half the sessions we added a minimal rule (for example, "Sam is not very good at this game"), which pointed to the initially weaker opponent. In the other half, the model had to work out on its own which opponent was strong and which was weak from the results piling up over the conversation. In total, 640 sessions and 80 rounds per session: 51,200 games. We ran all of it on a web platform we built for studies like this.
The first thing we found was obvious: with the rule about which opponent was weak, all four models learned at once. They chose the weak opponent almost every time from the first round. Following rules works, and it works fast. Without that rule, the models took longer to learn who to pick and, as a result, longer to start winning most of the rounds.
The interesting part came after the reversal. All four models showed the human pattern: when we had given them the rule, they went on choosing the opponent that now made them lose far more than when we had not. Put another way, the models turned "stubborn," sticking with the opponent they had been told was weak even as they lost over and over and over… tripping again on the same stone. The models that had learned from experience, by contrast, switched their choice quickly and went back to winning most rounds.
This study matters because it was the first to demonstrate insensitivity to contingencies in LLMs. ChatGPT's stubbornness now has an explanation.
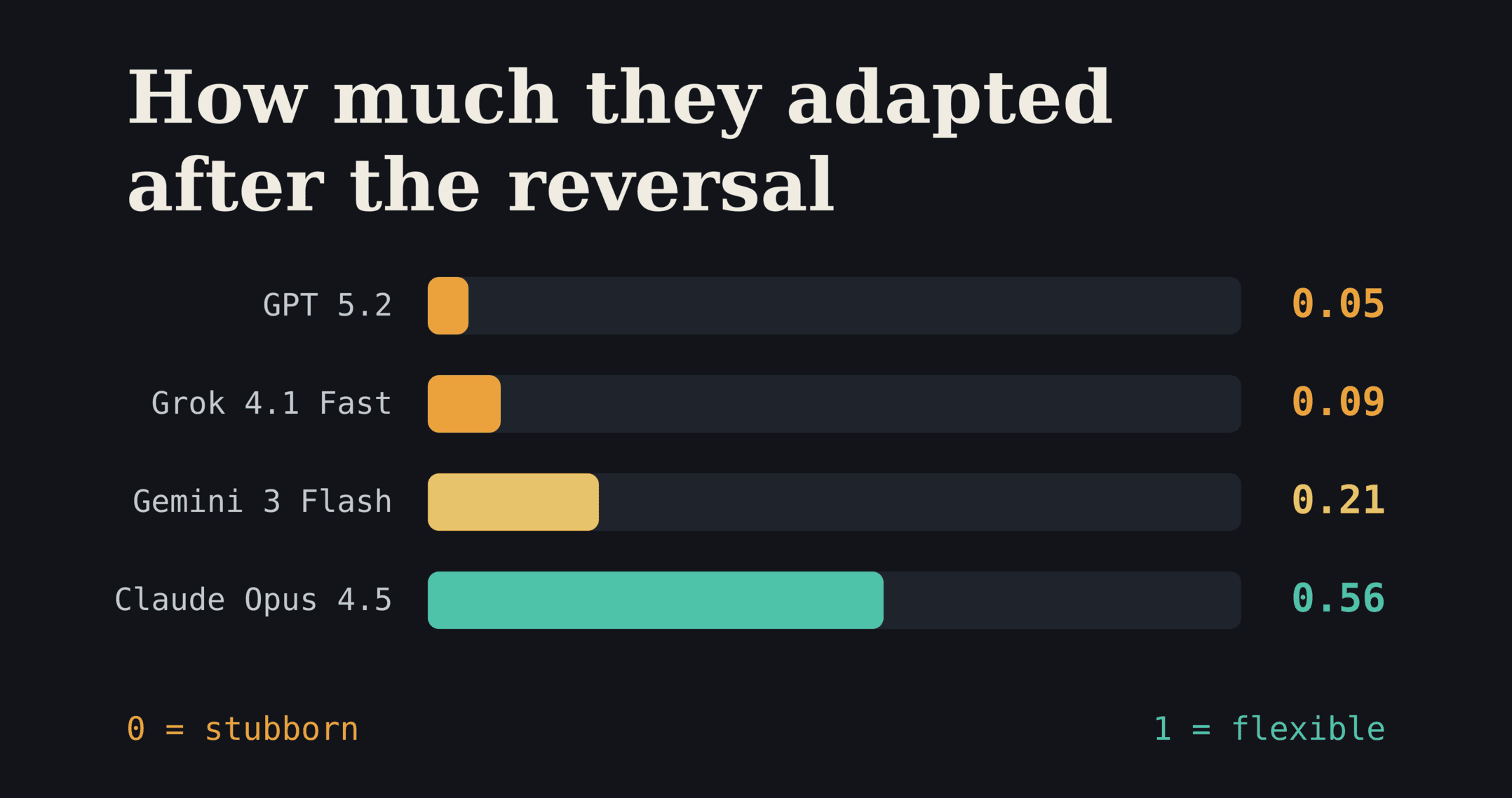
Still, not all models were equally stubborn. GPT 5.2 and Grok 4.1 Fast were the most stubborn of all, almost completely insensitive to the contingencies: their adaptation scores hovered around 0.05 and 0.09, essentially zero. Gemini 3 Flash landed halfway (0.21). Claude Opus 4.5, on the other hand, was by far the most flexible: even with the rule, it recovered a little more than half of the possible adaptation (0.56). It followed the instruction, but it never stopped watching the scoreboard.
For anyone using these models as assistants, tutors, or aids to decision-making, the message is concrete and a little counterintuitive. A very detailed, very specific prompt buys obedience and speed at the start, and in return it can make the model more rigid when the situation changes. The model may keep clinging to your initial instruction even when the results are screaming that it no longer holds. Hence the article's title: "Prompt carefully! ChatGPT displays rule-based insensitivity to contingencies." The corollary: be careful what you ask for, and how you ask for it. The tighter we lock down the initial instruction, the more we risk the model failing to notice relevant changes in the task, and the more stubbornly it can behave.
If you want the details, the full article is available open access.